Abstract
We present an approach for learning to translate an image from a source domain X to a target domain Y in the absence of paired examples.
1. Introduction

- Paired training data (left) consists of training examples {xi , yi} N i=1, where the correspondence between xi and yi exists .
- unpaired training data (right), consisting of a source set {xi} N i=1 (xi ∈ X) and a target set {yj}M j=1 (yj ∈ Y ), with no information provided as to which xi matches which yj .
-> reason about the stylistic differences between these two unpaired sets, and thereby imagine what a scene might look like if we were to “translate” it from one set into the other.
-> present a method that can learn to do the same: capturing special characteristics of one image collection and figuring out how these characteristics could be translated into the other image collection, all in the absence of any paired training examples.
we are given one set of images in domain X and a different set in domain Y
G : X → Y such that the output yˆ = G(x), x ∈ X, is indistinguishable from images y ∈ Y by an adversary trained to classify yˆ apart from y.
The optimal G thereby translates the domain X to a domain Yˆ distributed identically to Y .
Issue
However, such a translation does not guarantee that an individual input x and output y are paired up in a meaningful way.
-> standard procedures often lead to the wellknown problem of mode collapse, where all input images map to the same output image and the optimization fails to make progress.
↓
Therefore, we exploit the property that translation should be “cycle consistent”
“cycle consistent” : Mathematically, if we have a translator G : X → Y and another translator F : Y → X, then G and F should be inverses of each other, and both mappings should be bijections.
We apply this structural assumption by training both the mapping G and F simultaneously, and adding a cycle consistency loss
Combining this loss with adversarial losses on domains X and Y yields our full objective for unpaired image-to-image translation.
2. Related work
The key to GANs’ success is the idea of an adversarial loss that forces the generated images to be, in principle, indistinguishable from real photos.
Adopt an adversarial loss to learn the mapping such that the translated images cannot be distinguished from images in the target domain.
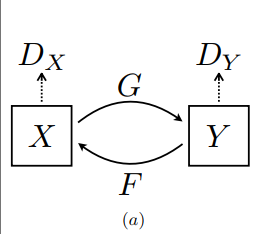
This model contains two mapping functions G : X → Y and F : Y → X, and associated adversarial discriminators DY and DX. DY encourages G to translate X into outputs indistinguishable from domain Y , and vice versa for DX and F.
introduce two cycle consistency losses that capture the intuition that if we translate from one domain to the other and back again we should arrive at where we started.
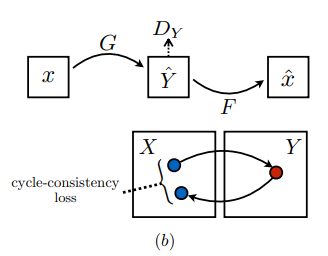
(b) forward cycle-consistency loss: x → G(x) → F(G(x)) ≈ x

(c) backward cycle-consistency loss: y → F(y) → G(F(y)) ≈ y
3. Formulation
3.1. Adversarial Loss

- matching the distribution of generated images to the data distribution in the target domain
- G tries to generate images G(x) that look similar to images from domain Y ->minG
- DY aims to distinguish between translated samples G(x) and real samples y. -> maxDY
- G aims to minimize this objective against an adversary D that tries to maximize it

- F : Y → X and its discriminator DX as well

3.2. Cycle Consistency Loss
- for each image x from domain X, the image translation cycle should be able to bring x back to the original image

3.3. Full Objective

4. Implementation
Network Architecture
This network contains three convolutions, several residual blocks , two fractionally-strided convolutions with stride 1 2 , and one convolution that maps features to RGB.
We use 6 blocks for 128 × 128 images and 9 blocks for 256×256 and higher-resolution training images.
Training details
For all the experiments, we set λ = 10 in Equation 3. We use the Adam solver with a batch size of 1. All networks were trained from scratch with a learning rate of 0.0002. We keep the same learning rate for the first 100 epochs and linearly decay the rate to zero over the next 100 epochs.
5. Results
5.1 Evaluation
Using the same evaluation datasets and metrics as “pix2pix” , we compare our method against several baselines both qualitatively and quantitatively.
5.1.1 Evaluation Metrics

Different methods for mapping labels↔photos trained on Cityscapes images. From left to right: input, BiGAN/ALI [7, 9], CoGAN [32], feature loss + GAN, SimGAN [46], CycleGAN (ours), pix2pix [22] trained on paired data, and ground truth.

Different methods for mapping aerial photos↔maps on Google Maps. From left to right: input, BiGAN/ALI [7, 9], CoGAN [32], feature loss + GAN, SimGAN [46], CycleGAN (ours), pix2pix [22] trained on paired data, and ground truth.
FCN score
The FCN metric evaluates how interpretable the generated photos are according to an off-the-shelf semantic segmentation algorithm.

Table 2: FCN-scores for different methods, evaluated on Cityscapes labels→photo.

Table 4: Ablation study: FCN-scores for different variants of our method, evaluated on Cityscapes labels→photo.
↓
Removing the GAN loss substantially degrades results, as does removing the cycle-consistency loss. We therefore conclude that both terms are critical to our results
5.1.5 Image reconstruction quality

The effect of the identity mapping loss on Monet’s painting→ photos.
The identity mapping loss helps preserve the color of the input paintings.
Identity loss
regularize the generator to be near an identity mapping when real samples of the target domain are provided as the input to the generator.
6. Limitations and Discussion

Figure 17: Typical failure cases of our method. Left: in the task of dog→cat transfiguration, CycleGAN can only make minimal changes to the input. Right: CycleGAN also fails in this horse → zebra example as our model has not seen images of horseback riding during training.
Although our method can achieve compelling results in many cases, the results are far from uniformly positive
We have also explored tasks that require geometric changes, with little success.
For example, on the task of dog→cat transfiguration, the learned translation degenerates into making minimal changes to the input (Figure 17).
Handling more varied and extreme transformations, especially geometric changes, is an important problem for future work.
'영상처리 > 딥러닝' 카테고리의 다른 글
| [RFA 논문 리뷰]Residual Feature Aggregation Network for Image Super-Resolution (0) | 2022.08.03 |
|---|---|
| [SRGAN 논문 리뷰]Photo-Realistic Single Image Super-Resolution Using a Generative AdversarialNetwork (0) | 2022.07.27 |
| SRGAN (0) | 2022.07.08 |
| CycleGAN (0) | 2022.07.08 |
| GAN (0) | 2022.07.06 |